Reinforcement Learning#
Classical Reinforcement Learning#
Markov Decision Process#
- Introduction
- What is Reinforcement Learning?
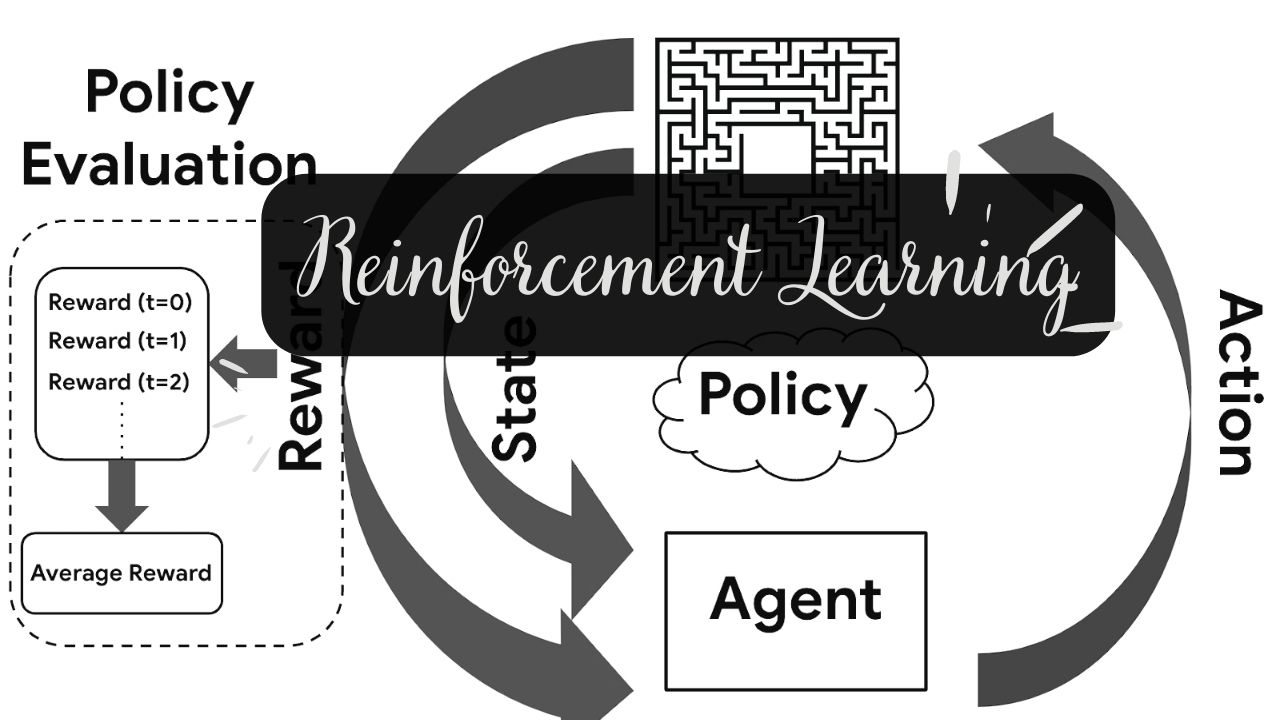
- Agent-Environment Interaction
- State Vectors
- Objective of RL Agent
- Actions & Policy
- Exploration vs Exploitation
- Markov State
- Markov Decision Process (MDP)
- Value Function
- Optimal Policy
- Model of the Environment
- RL vs Supervised Learning
- Inventory Management (MDP)
Fundamental Equations in RL#
- Introduction
- RL Equations – State Value Function
- RL Equations – Action Value Function
- Understanding the RL Equations
- Bellman Equations of Optimality
- Policy Improvement
- Introduction
Model-Based Method – Dynamic Programming#
- Dynamic Programming
- Policy Iteration – Algorithm
- Policy Evaluation – Prediction
- Policy Improvement – Control
- Policy Iteration – GridWorld
- Value Iteration
- Generalised Policy Iteration (GPI)
- Ad Placement Optimization (Demo)
Model-Free Methods#
- Introduction
- Intuition behind Monte-Carlo Methods
- Monte-Carlo Prediction & Demo
- Monte-Carlo Control
- Off Policy
- Temporal Difference
- Q-Learning with Pseudocode
- Cliff Walking Demo
- Ad Placement Optimization Demo -Q Learning
- OpenAI Gym -Taxi v2
Inventory Management Demo#
- Introduction
- Problem Statement
- MDP code
- Q-Learning code
- Results
Assignment -Classical Reinforcement Learning#
Assignment – Tic-Tac-Toe#
Deep Reinforcement Learning#
Introduction#
Want to build your own Atari Game? Learn the Q-function or policy using the various Deep Reinforcement Learning algorithms: Deep Q Learning, Policy Gradient Methods, Actor-Critic method.
Architectures of Deep Q Learning#
- Architectures of Deep Q Network
- DQN Architecture II – Visualisation
- DQN Demo – Cartpole Environment
- Double DQN – A DQN Variation
Deep Q Learning#
- Introduction
- Why Deep Reinforcement Learning?
- Parameterised Representation
- Generalizability in Deep RL
- Deep Q Learning
- Training in Deep Reinforcement Learning
- Replay Buffer
- Generate Data for Training
- Target in DQN
- When to stop training?
- Atari Game
- Introduction
Policy Gradient Methods#
- Introduction to Policy Gradient Methods
- The Intuition of Policy-Based Methods
- Comparing DQN and Policy-Based Methods
- Path Probability
- Objective Function
- Gradient of the Objective Function
- The Update Rule
- Step-by-Step Update
Actor-Critic Methods#
- Introduction
- The Need for Actor-Critic Methods
- Addressing the Problem of Variance
- Justification for Adding the Baseline
- Reducing Variance Using the Baseline
- Appropriate Choice of the Baseline
- Policy Gradient (REINFORCE)
- Actor-Critic Methods: Training
- Training Process: Summary
- Illustration: Defining the State Space
Reinforcement Learning Project#
Problem Statement#
Improve the recommendation of the rides to the cab drivers by creating an RL-based algorithm using vanilla Deep Q-Learning (DQN) to maximize the driver’s profits and in turn help in retention of the driver on the cab aggregator service.

Comments: