
Exploring Apache Hive: Capabilities and Scalability for Big Data Processing#
What is Hive?#
Apache Hive is a data warehousing and SQL-like query engine built on top of Hadoop. It provides a platform for processing large datasets stored in Hadoop Distributed File System (HDFS) and other data storage systems that integrate with Hadoop. Hive simplifies querying and managing big data with a familiar SQL-like syntax (HiveQL). Below are the key capabilities of Hive:
1. SQL-Like Querying (HiveQL)#
- Hive offers a SQL-like query language called HiveQL, making it accessible for users who are already familiar with traditional SQL. You can write queries to perform operations like select, join, filter, group by, and aggregate.
- HiveQL supports many common SQL constructs such as:
SELECT,INSERT,UPDATE,DELETE.- Aggregate functions:
SUM(),AVG(),COUNT(), etc. - Joins: Inner joins, outer joins, and cross joins.
- Subqueries, views, and unions.
2. Schema on Read#
- Hive follows a schema on read approach, meaning the data can be loaded in its raw form (e.g., unstructured or semi-structured), and the schema is applied when the data is read, not at the time of ingestion.
- This allows for flexibility in working with different types of data without enforcing strict data structure at the time of loading.
3. Integration with Hadoop and HDFS#
- Hive is designed to work seamlessly with Hadoop and HDFS for distributed storage and processing.
- It also supports other Hadoop ecosystem components like MapReduce, Apache Tez, and Apache Spark as execution engines.
4. Support for Large-Scale Data#
- Hive is capable of handling petabytes of data spread across a distributed Hadoop cluster.
- Data is processed in parallel across multiple nodes, making Hive scalable for very large datasets (millions or billions of records).
5. Data Storage Formats#
- Hive supports various storage formats, including:
- TEXTFILE (plain text, e.g., CSV).
- ORC (Optimized Row Columnar): Optimized for high compression and fast reading.
- Parquet: Columnar storage format optimized for big data.
- Avro: For schema-based serialization.
- SequenceFile: Binary format for key-value pairs.
- Columnar formats like ORC and Parquet are recommended for better query performance and storage efficiency.
6. Partitioning and Bucketing#
- Partitioning:
- Hive allows partitioning of tables based on specific columns (e.g.,
Year,Month). Partitioning helps improve query performance by scanning only the relevant subset of data.
- Hive allows partitioning of tables based on specific columns (e.g.,
- Bucketing:
- Bucketing distributes data into smaller sets (buckets) within partitions. This further optimizes query execution by allowing data retrieval from specific buckets.
7. Indexes#
- Hive provides support for creating indexes on tables, allowing faster lookups for certain queries. Although Hive’s indexing capabilities are not as advanced as traditional RDBMS, they help with query optimization.
8. Support for Complex Data Types#
- Hive supports complex data types such as:
- ARRAY: A collection of ordered elements.
- MAP: Key-value pairs.
- STRUCT: Custom structures with multiple fields.
- This allows Hive to handle semi-structured and hierarchical data formats like JSON.
9. User-Defined Functions (UDFs)#
- Hive allows users to create their own User-Defined Functions (UDFs) in Java or Python to perform custom transformations on data that go beyond built-in functions.
- There are also User-Defined Aggregation Functions (UDAFs) and User-Defined Table-Generating Functions (UDTFs) for complex processing.
10. ACID Transactions#
- Hive supports ACID (Atomicity, Consistency, Isolation, Durability) transactions, allowing INSERT, UPDATE, and DELETE operations. This provides more control over data mutation and ensures data integrity.
- Full ACID compliance (row-level transactions) is supported for ORC tables.
11. Data Warehousing Features#
- Views: Hive supports the creation of views, which are logical constructs for saving query results or complex query logic.
- Materialized Views: Starting with Hive 3.x, it supports materialized views to improve performance by storing query results for future use.
- Indexes: Basic indexing can be done to improve performance.
12. Connectivity and Integration#
- Hive can be integrated with other data platforms and tools through standard interfaces such as:
- ODBC/JDBC: Allows external tools like BI platforms to connect to Hive.
- Apache HBase: Hive can access NoSQL data in HBase.
- Apache Spark: You can run Hive queries using Apache Spark for improved processing speed.
- Data Warehousing Tools: Integrates well with ETL tools and big data platforms like Apache Pig, Flume, Sqoop, and more.
13. Support for Machine Learning Libraries#
- Hive integrates with tools like Apache Mahout and Apache Spark MLlib for machine learning tasks using Hive data.
- You can use data stored in Hive for training machine learning models in these libraries.
14. Security Features#
- Hive integrates with Kerberos for authentication and supports role-based access control (RBAC).
- It also offers encryption for data at rest and data in transit, ensuring compliance with security policies.
15. Optimized Query Processing#
- Cost-Based Optimizer (CBO): Hive’s CBO optimizes query plans based on data statistics, making queries more efficient.
- Query Optimization Techniques: Hive uses techniques like predicate pushdown, map-side joins, vectorization, and parallel execution to optimize queries.
16. Execution Engines#
- Hive supports multiple execution engines, including:
- MapReduce: The default execution engine for large-scale batch processing.
- Apache Tez: Provides faster DAG-based execution than MapReduce.
- Apache Spark: Available as an engine for higher performance, especially with in-memory processing.
17. Data Load and ETL Processing#
- Hive supports ETL (Extract, Transform, Load) operations and can read data from multiple sources, transform it, and load it into tables.
- Data ingestion: You can load data from HDFS, local file systems, or other Hadoop ecosystem components.
18. Scalability and Fault Tolerance#
- Hive can scale to handle massive datasets across thousands of nodes. Its fault tolerance relies on Hadoop’s underlying mechanisms like replication in HDFS and failure recovery during job execution.
In Summary:#
Hive’s capabilities make it a powerful tool for querying and analyzing large datasets using an SQL-like interface. It is well-suited for batch processing, ETL tasks, and data warehousing solutions in big data environments, offering flexibility in terms of data formats, storage, and query optimization. However, for real-time or low-latency applications, other Hadoop ecosystem tools like Apache HBase or Presto might be more suitable.
What are the components of Hive Architecture and how it intereacts with Hadoop.#
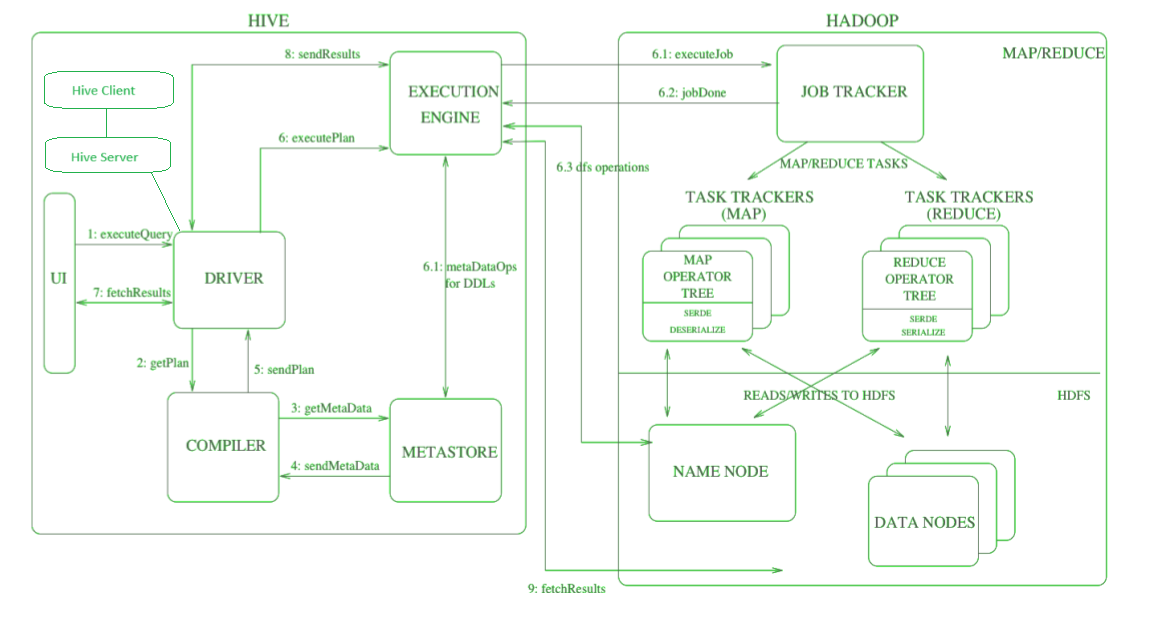
- Hive Client: Thrift Server, JDBC driver, and ODBC driver. They interact with Hive Server and in turn it deals with Hive Driver.
- UI : Hive Web UI, CLI. They interact with Hive Driver directly (no need of Hive Server)
- Compiler: Execution plan with the help of the table in the database and partition metadata observed from the metastore are generated by the compiler. This parses queries, does semantic analysis on the different query blocks and query expression.
- Execution Engine: MapReduce, Apache Tez, Apache Spark
- MetaStore - It is a central repository that stores all the structure information of various tables and partitions in the warehouse. It also includes metadata of column and its type information, the serializers and deserializers which is used to read and write data and the corresponding HDFS files where the data is stored.
Can Hive handle 1 billion records of usecase?#
Yes, Hive can handle 1 billion records and even more, as it is designed to work with very large datasets. Hive is built on top of Hadoop, which uses the distributed storage and processing capabilities of the Hadoop Distributed File System (HDFS). This architecture makes it highly scalable for big data processing. However, the performance will depend on several factors:
Factors Affecting Hive’s Scalability:#
Cluster Size:
- The number of nodes in your Hadoop cluster will significantly impact Hive’s ability to handle large datasets. With more nodes, data can be partitioned and distributed effectively, leading to faster query execution.
Data Storage Format:
- Text format (CSV), as used in your table (
STORED AS TEXTFILE), is not the most efficient for big data. For better performance, consider using optimized storage formats like:- ORC (Optimized Row Columnar) or Parquet.
- These formats support compression, indexing, and faster read/write operations, which are ideal for large-scale data.
- Text format (CSV), as used in your table (
Partitioning and Bucketing:
- Hive tables can be partitioned based on columns (e.g., Year, Month) to narrow down the amount of data scanned for queries.
- Bucketing can further distribute data within partitions to optimize query execution on large datasets.
Query Optimization:
- Using advanced features like Hive Query Optimization (Tez engine), predicate pushdown, and vectorization can significantly enhance query performance for large tables.
Resource Allocation:
- Resource allocation in terms of memory, CPU cores, and I/O bandwidth will also determine Hive’s ability to handle large volumes of data. Proper tuning of these resources is essential for handling billion-record tables.
Practical Considerations:#
- Hive is used in many industry scenarios where datasets range from millions to hundreds of billions of records.
- For a 1 billion record table, if your cluster is well-configured (e.g., has sufficient nodes and resources), Hive should be able to manage it without issues.
Recommendations for Handling Large Datasets:#
- Use ORC or Parquet format instead of
TEXTFILE. - Enable partitioning on columns that are commonly used for filtering (e.g., Year, Month).
- Monitor and scale your cluster based on data growth and query performance.
With these optimizations, Hive can handle 1 billion or more records effectively, making it a robust choice for big data processing.
How to create Hive table from external data?#
CREATE EXTERNAL TABLE airlines( SNo int, Year int, Month int, DayofMonth int, DayOfWeek int, DepTime int, CRSDepTime int, ArrTime int, CRSArrTime int, UniqueCarrier string, FlightNum int, TailNum string, ActualElapsedTime int, CRSElapsedTime int, AirTime int, ArrDelay int, DepDelay int, Origin string, Dest string, Distance int, TaxiIn int, TaxiOut int, Cancelled int, CancellationCode string, Diverted int, CarrierDelay int, WeatherDelay int, NASDelay int, SecurityDelay int, LateAircraftDelay int) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,’ STORED AS TEXTFILE LOCATION ‘/common_folder/airlines/’ tblproperties (“skip.header.line.count”=“1”);
This Hive code creates an external table called airlines to store flight data with various attributes. Here’s a breakdown of what it does:
Key Sections of the Code:#
CREATE EXTERNAL TABLE airlines:
- An external table is being created. An external table means the data is stored outside of Hive’s control. Hive will not delete the data if the table is dropped.
Column Definitions:
- The table contains a list of columns with their data types:
SNo: Serial number (int).Year,Month,DayofMonth,DayOfWeek: Date-related fields (int).DepTime,CRSDepTime,ArrTime,CRSArrTime: Departure and arrival times, both actual and scheduled (int).UniqueCarrier: Carrier code (string).FlightNum: Flight number (int).TailNum: Aircraft tail number (string).ActualElapsedTime,CRSElapsedTime,AirTime,ArrDelay,DepDelay: Time-related fields, like actual/scheduled elapsed times and delays (int).Origin,Dest: Origin and destination airports (string).Distance: Distance of the flight (int).TaxiIn,TaxiOut: Time spent on taxiing (int).Cancelled: Whether the flight was canceled (int).CancellationCode: Reason for cancellation (string).Diverted: Whether the flight was diverted (int).CarrierDelay,WeatherDelay,NASDelay,SecurityDelay,LateAircraftDelay: Delay-related fields due to specific reasons (int).
- The table contains a list of columns with their data types:
ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,’:
- This defines that the data in the external file is delimited by commas, meaning it is CSV format.
STORED AS TEXTFILE:
- Specifies that the data is stored as a plain text file.
LOCATION ‘/common_folder/airlines/’:
- The data for this external table is stored in the specified directory
/common_folder/airlines/.
- The data for this external table is stored in the specified directory
tblproperties (“skip.header.line.count”=“1”):
- This indicates that the first row in the file is a header (column names), so Hive should skip the first line when querying the table.
Summary:#
This code creates an external table airlines in Hive to read CSV data from the location /common_folder/airlines/. It specifies the structure of the data with column names and types, and tells Hive to skip the first header line when processing the CSV file.
For the above created table, how to create year wise partition?#
insert overwrite table airlines_partitioned partition(Year)
select SNo,
Month,
DayofMonth,
DayOfWeek,
DepTime,
CRSDepTime,
ArrTime,
CRSArrTime,
UniqueCarrier,
FlightNum,
TailNum,
ActualElapsedTime,
CRSElapsedTime,
AirTime,
ArrDelay,
DepDelay,
Origin,
Dest,
Distance,
TaxiIn,
TaxiOut,
Cancelled,
CancellationCode,
Diverted,
CarrierDelay,
WeatherDelay,
NASDelay,
SecurityDelay,
LateAircraftDelay,
Year
from airlines;
How to perform SQL operations on partitioned Hive table?#
It is normal sql query, which you may have seen in mysql, oracle, tsql. You need to take care of supported functions, keywords and uppre/lower case of the keywords.
Query below is performed on partitioned table, because this table is partitioned on year therefore performing “group by” on year is quick. This query will display average taxi-out time year-on-year basis.
SELECT Year, avg(TaxiOut) as avg_TaxiOutTime from airlines_partitioned GROUP BY Year;
Common Hive Commands#
hive> show databases;
hive> create database if not exists demo;
hive> describe database extended demo;
hive> drop database if exists demo;
hive> drop database if exists demo cascade;
hive> use demo;
hive> show tables;
hive> drop table new_employee;
hive> Alter table emp rename to employee_data;
hive> Alter table emp add columns(father_name string);
hive> Alter table emp change old_column_name new_column_name datatype;
Internal Table, these tables are stored in a subdirectory under the directory defined by hive.metastore.warehouse.dir (i.e. /user/hive/warehouse). If we try to drop the internal table, Hive deletes both table schema and data.
hive> create table demo.employee (Id int, Name string , Salary float)
row format delimited
fields terminated by ',' ;
hive> describe demo.employee
hive> create table if not exists demo.copy_employee like demo.employee;
External Table, The external table allows us to create and access a table and a data externally. The external keyword is used to specify the external table, whereas the location keyword is used to determine the location of loaded data.
hive> hdfs dfs -mkdir /HiveDirectory #(create directory)
hive> hdfs dfs -put hive/emp_details /HiveDirectory #(copy file to this directory)
hive> create external table emplist (Id int, Name string , Salary float)
row format delimited
fields terminated by ','
location '/HiveDirectory';
hive> load data local inpath '/home/codegyani/hive/emp_details' into table demo.employee;
The partitioning in Hive means dividing the table into some parts based on the values of a particular column like date, course, city or country. The advantage of partitioning is that since the data is stored in slices, the query response time becomes faster.
Static Partitioning
hive> create table student (id int, name string, age int, institute string)
partitioned by (course string)
row format delimited
fields terminated by ',';
Load the data of another file into the same table and pass the values of partition columns
hive> load data local inpath '/home/codegyani/hive/student_details1' into table students partition(course= "java");
hive> load data local inpath '/home/codegyani/hive/student_details1' into table students partition(course= "ml");
hive> select * from student where course="java";
Dynamic partioning, In dynamic partitioning, the values of partitioned columns exist within the table. So, it is not required to pass the values of partitioned columns manually.
hive> set hive.exec.dynamic.partition=true;
hive> set hive.exec.dynamic.partition.mode=nonstrict;
hive> create table stud_demo(id int, name string, age int, institute string, course string)
row format delimited
fields terminated by ',';
hive> load data local inpath '/home/codegyani/hive/student_details' into table stud_demo;
hive> create table student_part (id int, name string, age int, institute string)
partitioned by (course string)
row format delimited
fields terminated by ',';
hive> insert into student_part partition(course)
select id, name, age, institute, course from stud_demo;
How to visualize Hive query data?#
Hive is not a data visualization tool, but a tool for data preparation engine for querying, transforming, and aggregating large datasets. You can integrate Hive with BI tools, notebooks, and visualization libraries to create visualizations based on its data. You can use Tableau, Power BI for visual reporting, Apache Zeppelin or Jupyter Notebooks for interactive data exploration and Apache Superset for open-source visualization. Here’s is summary of tools for visualization:
1. Hive as a Data Source for BI Tools#
- Hive can act as a backend for querying large datasets, and the results of those queries can then be fed into visualization tools. Many Business Intelligence (BI) and visualization tools support Hive as a data source via JDBC/ODBC connectors.
- Examples of BI tools that can connect to Hive include:
- Tableau
- Power BI
- QlikView
- Looker
- Google Data Studio
- These tools can directly query Hive, and you can use the query results to create visualizations like charts, graphs, dashboards, and reports.
2. Hive with Apache Zeppelin or Jupyter Notebooks#
- Apache Zeppelin:
- Zeppelin is a web-based notebook that can connect to Hive. You can run Hive queries within Zeppelin and visualize the results using built-in charting capabilities (line charts, bar graphs, pie charts, etc.).
- Jupyter Notebooks:
- You can also use Jupyter Notebooks with libraries like PyHive or Impyla to connect to Hive, execute queries, and visualize data using Matplotlib, Seaborn, or Plotly.
3. Hive with Data Visualization Libraries in Spark#
- If you are using Hive with Apache Spark as the execution engine, you can load Hive data into Spark DataFrames and use Spark’s integration with Python or Scala to create visualizations.
- Libraries like Matplotlib, Seaborn, Plotly, or Altair can then be used to visualize Spark DataFrames.
4. Integrating Hive with Superset#
- Apache Superset is an open-source data visualization tool that integrates with Hive. You can query data in Hive directly within Superset and create visual dashboards with charts, tables, and maps.
5. Hive as Part of the ETL Pipeline#
- Hive can be part of your ETL pipeline, transforming raw data into aggregated or structured formats that are more suitable for visualizations.
- After processing data in Hive, the cleaned or transformed data can be exported to another data warehouse, such as Apache Kylin, Presto, or Elasticsearch, which are often more optimized for real-time visualizations.
6. Limitations of Using Hive Directly for Visualization#
- Latency: Hive is designed for batch processing and may not provide the low-latency query performance required for real-time or interactive data visualizations.
- Execution Speed: Depending on your execution engine (MapReduce, Tez, Spark), Hive queries can be slow, which may not be ideal for quick, interactive visualizations.
- Real-Time Use Cases: Hive is not suitable for real-time streaming data visualizations. For real-time or near-real-time analytics, tools like Apache Kafka with Apache Druid or ClickHouse are more appropriate.
Code References#
- javatpoint.com/hive
Hashtags#
#BigData #ApacheHive #Hadoop #DataWarehousing #DistributedComputing #DataProcessing #ETL #HiveQL #DataOptimization #CloudComputing #ScalableData

Comments: